이번에는 SORT논문에 대해서 학습한 내용을 적어보려고 합니다.

Abstract
- the main focus is to associate object efficiently for online and realtime application
- Using rudimentary combination (kalman filter, hungarian algorithm)
- detection quality is identified as a key factor influencing tracking performence
- very fast
Introduction
- lean implementation of tracking by detection
- because of just using the previous and the current frame, so this work is efficient
- nowdays benchmark are shown that we make the track more simple and more well it can perform
- because the detection quality is a key factor of tracking quality
- MOT problem can be viewed as a data association problem
- nowdays many tracker are using various methods
- a resurgence of mature data association
- the only tracker is also the top ranked tracker, suggesting that the dectection quality could be holding back the other trackers
- occam's razor -> only the bbox poisition and size are used for motion estimation and data association
- this work focuses on efficient and reliable handling of the common frame to frame associations
- CNN + Kalman filter and hungarian algorim <- this formulation of tracking facilitates both efficiency and reliability
tracking을 두가지 분류로 나눌수 있다.
online tracking vs offline tracking
- offline tracking : betch based tracking
tracking by detection vs detection by tracking
METHODOLOGY
1.detection
2.propagating object states into future frames
3.associating current detection with existing objects
4.managing the lifespan of tracked objects
Estimation model
used a linear constant velocity model which is independent of other objects and camera motion

u : horizontal pixel of the center of the target
v : vertical pixel of the center of the target
s : scale of the target's bounding box
r : aspect ratio of the target' bounding box -> aspect ration is considered to be constant
when a detection is associated to a target -> the detected bbox is used to update the target state where the velocity components are solved optimally via a kalman filter framework
if no detection is associated to the target, its state is simply predicted without correction using the linear velocity model
Data association
- The assignment cost matrix is then computed as the intersection-over-union (IOU) distance between each detection and wall predicted bounding boxes from the existing targets.
- The assignment is solved optimally using the Hungarian Algorithm.
- A minimum IOU is imposed to reject assignments where the detection to target overlap is less than IOUmin.
Creation and Deletion of Track Identities
- For creating trackers, we consider any detection with an overlap less than IOUmin to signify the existence of an untracked object.
- Tracks are terminated if they are not detected for Tlost frame
CONCLUSION
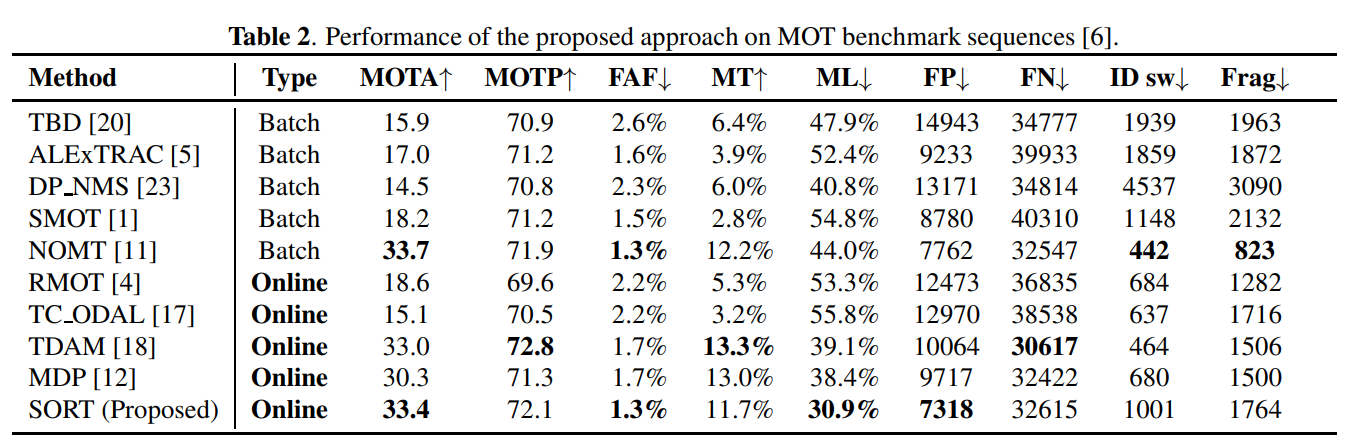
- Tracking quality is highly dependent on detection performance and by capitalising on resent developments in detection
- SORT achieves best in class performance with respect to both speed and accuracy
추가 공부 해야할것
- kalman filter : 센서의 노이즈를 잡기위한 재귀필터
- humgarian algorithm : assignment problem 을 해결하기 위한 optimal solution
- Occam's Razor : 문제를 해결하기 위한 2가지의 방법이 있을때, 좀 더 쉽고 간단한 방법을 선택하는것
단어 정리
- pragmatic: 실용적인, 실용주의의, 현실적인
- rudimentary: 기초적인, 초보적인, 기본적인
- lean implementation: 간결한 실행, 미약한 구현
- resurgence: 부활, 재생, 되살아남
- hypothesis tracking: 가설 추적, 가설 추론
- could be holding back: 지연시킬 수 있다, 방해하고 있을 수 있다
- explicit: 명시적인, 분명한
- myriad: 무수히 많은, 수많은
- robust: 견고한, 강건한, 튼튼한
- leverage: 영향력을 행사하다, 활용하다
- pragmatic: 실용적인, 실용주의의, 현실적인
- impractical: 비현실적인, 실현불가능한
추가로 궁금한점 왜 kalman filter에서 linear하게 문제를 바라봤을까? 가속도나 다른방법으로는??
reference
https://arxiv.org/pdf/1602.00763.pdf
https://github.com/abewley/sort
GitHub - abewley/sort: Simple, online, and realtime tracking of multiple objects in a video sequence.
Simple, online, and realtime tracking of multiple objects in a video sequence. - abewley/sort
github.com
'프로그래밍 > 논문 리뷰' 카테고리의 다른 글
| 논문 약어 정리 (i.e., et al, e.g.) (0) | 2024.03.25 |
|---|





