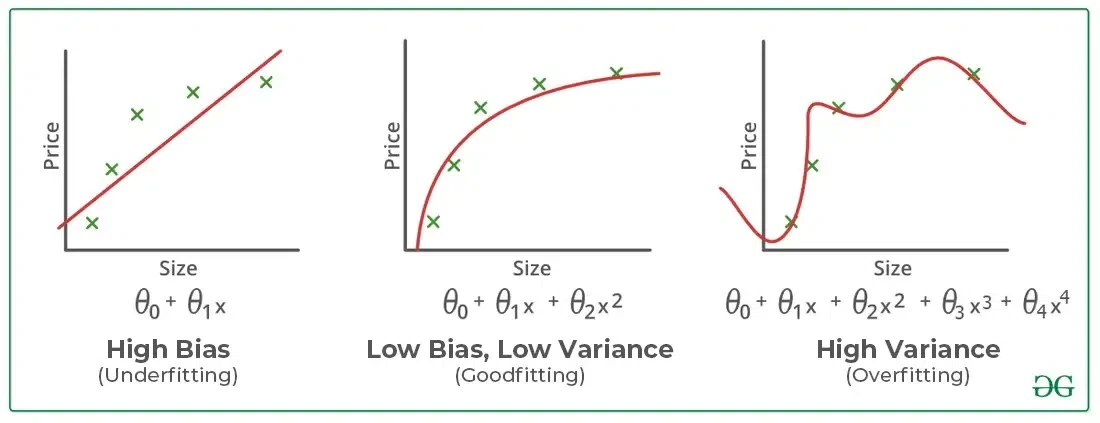
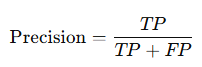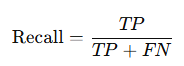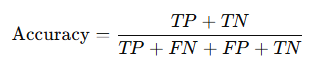A perceptron is a simple algorithm that takes multiple input signals and produces a single output signal.
For example, imagine someone hits you. Depending on where you are hit, you may or may not make a sound. If multiple parts of your body are hit (multiple input signals), your response (e.g., saying "Ouch!") can be considered the output signal (0: no sound, 1: "Ouch!"). The perceptron is designed based on this concept and can be represented mathematically.
Structure of a Perceptron
The structure of a perceptron consists of the following components:
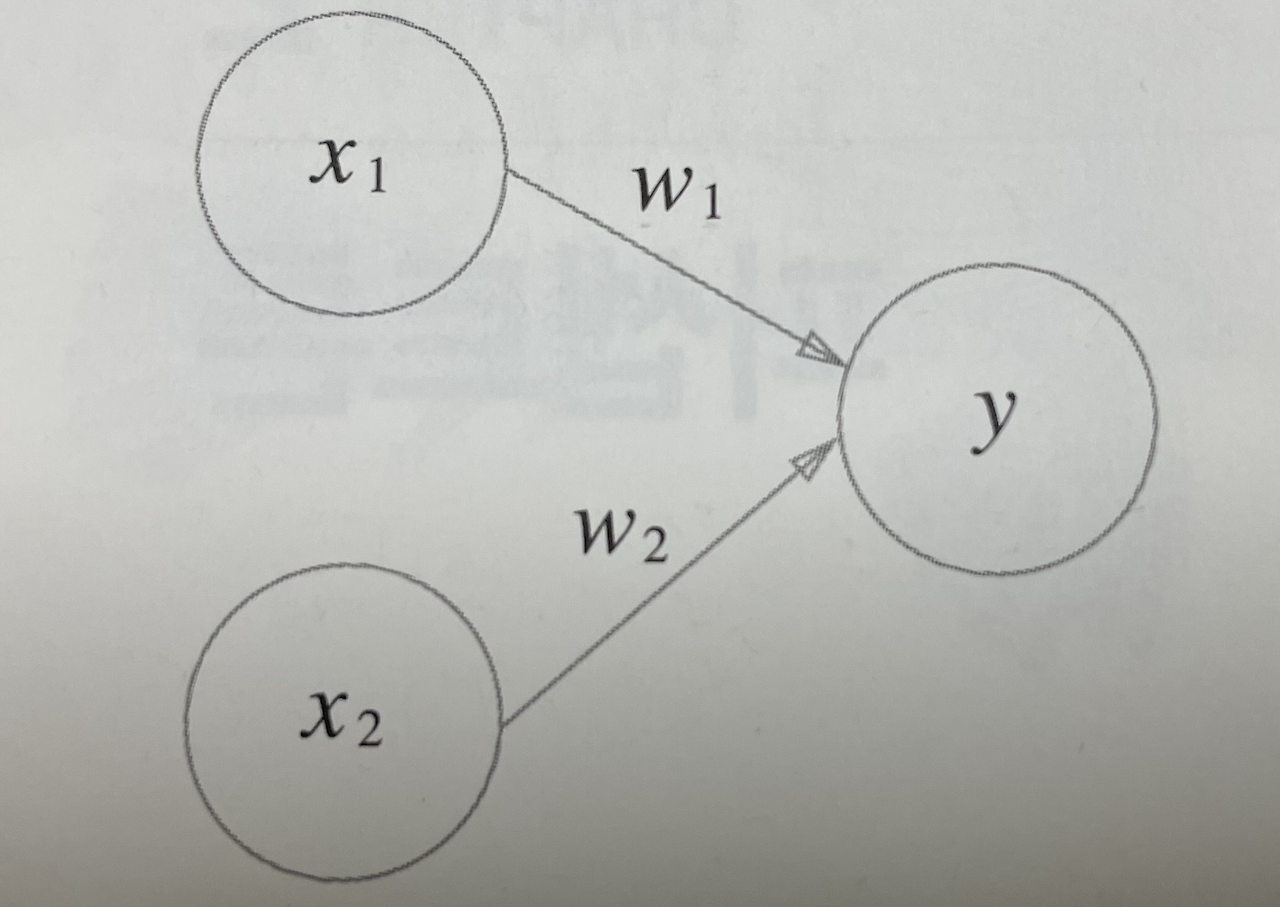
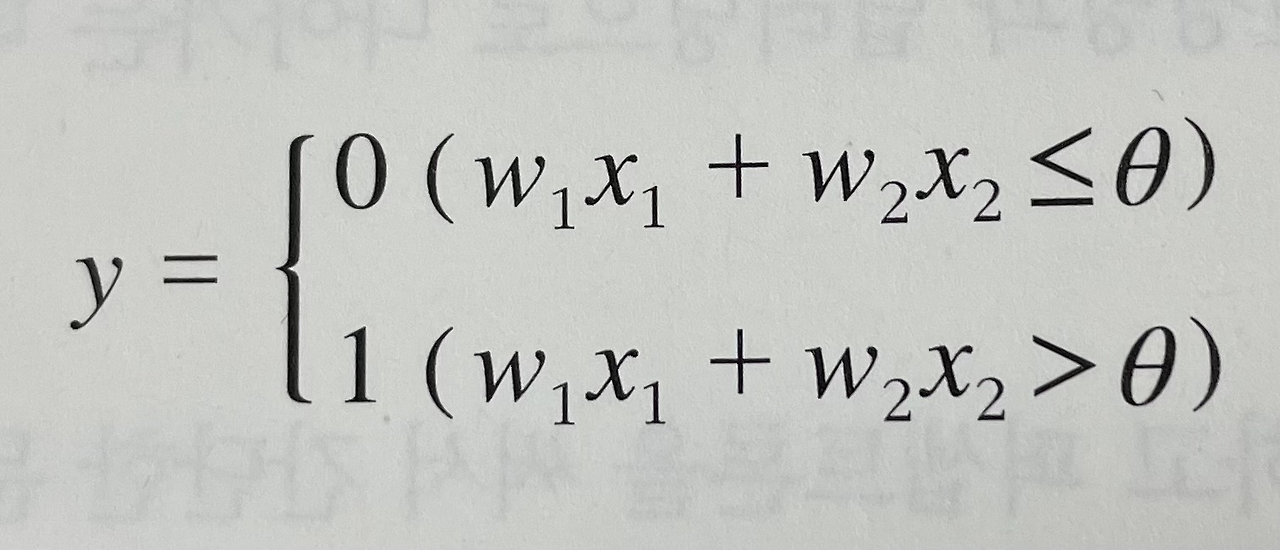
- x₁, x₂: Input signals
- w₁, w₂: Weights (determining the importance of each input)
- θ (Theta): Bias (Threshold value)
The perceptron computes the output y using the following equation:
If (w₁ * x₁ + w₂ * x₂) > θ, then y = 1
Else, y = 0In other words, if the weighted sum of the input signals exceeds a certain threshold θ, the perceptron outputs 1; otherwise, it outputs 0.
Implementing Logic Gates with Perceptrons
A perceptron can be used to implement simple logic circuits. Let’s look at an example: AND gate.
What is an AND Gate?
An AND gate outputs 1 only when both input signals x₁ and x₂ are 1. The following truth table illustrates this behavior:
x₁x₂y (Output)
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Implementing an AND Gate with a Perceptron
Using the perceptron equation, we can set appropriate values for the weights and threshold to achieve the AND gate behavior:
- w₁ = 0.5
- w₂ = 0.5
- θ = 0.6
Now, let's check if the perceptron correctly implements the AND gate:
If (w₁ * x₁ + w₂ * x₂) ≤ θ, then y = 0
If (w₁ * x₁ + w₂ * x₂) > θ, then y = 1By substituting values from the truth table, we see that the perceptron correctly produces 1 only when both x₁ and x₂ are 1, matching the AND gate.
Implementing OR and NAND Gates
Similarly, by adjusting the weights and bias values, we can implement other logic gates like OR and NAND. For example:
- OR Gate: Adjust weights so that the perceptron activates when either input is 1.
- NAND Gate: Use negative weights and bias to invert the AND gate output.
Conclusion
The perceptron is a simple yet powerful algorithm that can be used to implement logic gates. While it is a basic model, it serves as the foundation for modern deep learning neural networks. Understanding perceptrons helps in grasping the core ideas behind more advanced machine learning models.
'프로그래밍 > 머신러닝&딥러닝' 카테고리의 다른 글
| Epoch, Batch, and Iteration in Deep Learning (0) | 2025.03.20 |
|---|---|
| (Terminology) Precision, Recall, and Accuracy (0) | 2025.03.16 |
| What Is Data Annotation (Labeling)? (0) | 2025.03.13 |
| 퍼셉트론(Perceptron)이란 무엇인가? (0) | 2024.11.21 |
| Epoch, batch, iteration (0) | 2024.03.24 |