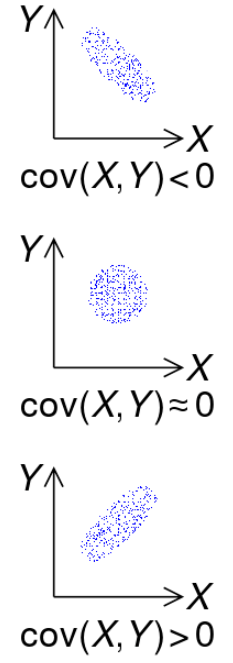
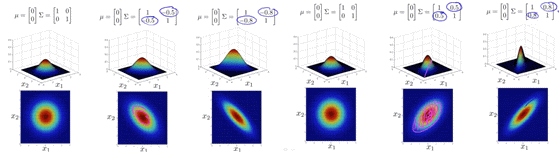
헝가리안 알고리즘을 보다 보면 matching과 vertex cover이라는 용어가 계속 나온다.
이게 도대체 무슨 의미길래 계속 나오는가?
vertex cover란?
어떠한 그래프에서의 접점인데, 모든 간선들을 커버하는 접점
도대체 접점은 뭐고, 그래프는 뭐고, 간선은 뭔데???
이러한 기본 지식을 설명하려고 한다.
그래프(graph)
"그래프란 정점(vertex)들이 간선(edge)들로 연결되어 있는 구조"
아래 그림을 보면 이해가 쉽다.
vertex란 선과선이 연결되는 지점, 끝점이며
edge란 정점들을 연결하는 간선이다.
아래에는 6개의 vertex와 5개의 edge가 있는 그래프이다.

자 그러면, 다시 vertex cover의 정의로 돌아가려고 한다.
vertex cover
"어떠한 그래프에서의 접점인데, 모든 간선들을 커버하는 접점"
이제 좀 이해가 가는가?
아래의 각각의 그래프에서 빨간점은 모두 vertex cover가 된다.
쉽게 말해 빨간점과 빨간 점에 이어진 선을 모두 제거하게 되면
남아있는 것이 없는 상태가 되는 vertex의 집합을 vertex cover라고 한다.



해당 내용을 기반으로 헝가리안 알고리즘을 다시 한번 보게 되면, 다른 블로그들의 설명을 좀 더 쉽게 이해할 수 있을 것이다.
https://billionaire-hossa.tistory.com/36
reference
https://namnamseo.tistory.com/entry/Matching%EA%B3%BC-Vertex-cover
Matching과 Vertex cover
Matching이란, 어떠한 그래프에서 간선을 잘 고른 것이다. 이 때 이 간선들은 서로 어떠한 점에서도 만나지 않아야 한다. 즉, 그래프에서 한 간선을 잡고, 그 간선과 양 끝 점을 제외한 그래프에서
namnamseo.tistory.com
https://namnamseo.tistory.com/entry/Tree%EC%9D%98-%EA%B8%B0%EC%B4%88?category=589725
트리의 기초
트리(tree)는 그래프의 일종이다.그래프란 정점(vertex)들이 간선(edge)들로 연결되어있는 구조를 뜻한다. 정점은 node, 노드라고도 부른다.지하철 노선도에서 각 역이 정점, 이웃한 역을 잇는 노선이
namnamseo.tistory.com
'프로그래밍 > 수학' 카테고리의 다른 글
| 확률 변수 & 확률 함수 (5) | 2024.09.30 |
|---|---|
| 내적 (Dot product) (3) | 2024.09.29 |
| Hungarian Algorithm (헝가리안 알고리즘이란?) (2) | 2024.03.29 |
| 자연상수 𝑒(exponential)란 무엇인가요? (0) | 2024.02.20 |
| 공분산(covariance)이란? (0) | 2023.03.16 |